memo 01
Marianは、Markdownノートを蓄積するワークスペースです。本文に書いた [[リンク]] は相手ノートを参照し、逆方向はバックリンクとして自動で集まります。
Marian · Experience Base
記憶は保存ではない。判断の材料である。
In 30 seconds
検索ではなく、想起。保存ではなく、判断。Marianはあなたの記録を、AIエージェントが使える長期記憶に変えます。回答には必ず出典が付き、記憶は夜のあいだに統合され、過去の経験が次の判断の材料になります。
こんな人のために
こういう用途ではない
Concept
Marianは、Markdownノートを蓄積するワークスペースです。本文に書いた [[リンク]] は相手ノートを参照し、逆方向はバックリンクとして自動で集まります。
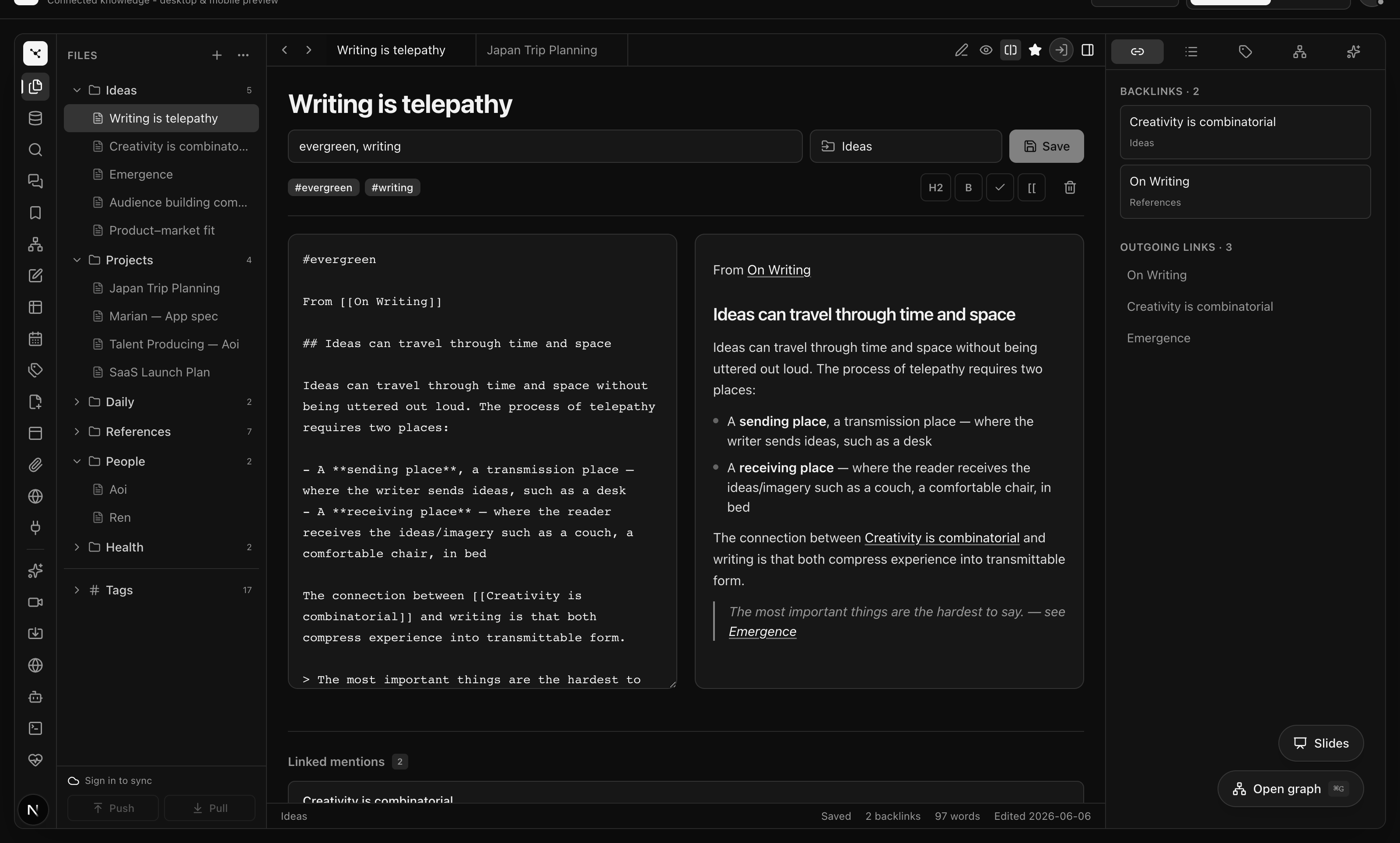
画面は3つに分かれます。左に保管庫とフォルダ、中央にノートと検索結果、右に関連ノートとグラフ。タグ、人物、プロジェクトでノートを横断できます。
AIアシスタントには、開いているノートや関連ノートを文脈としてまとめて渡せます。要約、比較、タスク抽出、次アクションの草案に利用できます。
Features
ノート本文に [[リンク]] を書くと相手ノートを参照し、逆方向はバックリンクとして自動で集まります。関連ノートを双方向にたどれます。
保管庫全体をグラフ表示。どのノートがハブで、どれが孤立しているかを一目で確認できます。フォルダ単位で色分けされます。
選んだノート・リンク・タグをまとめてAIに渡し、要約、比較、タスク抽出、次アクションの草案を生成します。
PCの作業画面とスマホのクイック入力で、同じ保管庫を編集。どちらから入力しても同じノートに反映されます。
Workspace
左側にフォルダと主要機能、中央にノートと検索結果、右側に関連ノートとグラフを同時に表示します。開いているノートと、それにつながる文脈を並べて確認できます。
デスクトップは編集と探索、モバイルは確認とクイック入力に向いています。どこから入力しても、ノートは同じ保管庫に積み上がります。
Workflow
Marianでの作業は4ステップです。ノートを取り込み、[[リンク]]とタグでつなぎ、関連ノートをAIに渡し、できた成果を別のノートで再利用します。
メモ、URL、ファイル、会話を保管庫に保存します。本文はMarkdownで残り、あとから検索できます。
[[リンク]] とタグでノートを関連付け。バックリンクとグラフが自動で更新されます。
関連ノートとリンクを束ねてAIに渡します。短い指示でも、保管庫の内容に即した回答が返ります。
調査ログ、意思決定、テンプレートを別のノートや案件から呼び出して使い回します。
> bundle vault --topic lp
> attach 12 notes, 8 links
> draft proposal, brief, pr summary
![Marian の知識グラフ。ノートが [[リンク]] でつながり、ドットの大きさはリンク数を表す。](/graph-preview.png?dpl=dpl_3K2Gqai8wS2uWup35DZqkAxQwCiu)
Graph
グラフは飾りではありません。どのノートが中心か、どのテーマが孤立しているか、同じ人物やプロジェクトに関係する記録がどこへ広がっているかを確認するための地図です。ドットの大きさはリンク数を表します。
ノードをクリックすればそのノートを開けます。フォルダ単位で色分けされ、タグやAIが提案するつながりも重ねて表示できます。
Audience
結論だけでなく、根拠、引用、反論、次の問いをノートに残し、[[リンク]]でつなげます。同じテーマに戻ったとき、バックリンクから前回の記録をたどれます。
フォルダとタグでノートを整理し、人物やプロジェクトをまたいでリンクできます。グラフで、案件をまたいだつながりを確認できます。
関連ノート、タグ、グラフを文脈としてAIにまとめて渡せます。毎回背景を書き直さなくても、保管庫の内容に沿った回答が得られます。
Principles
ノート、AI、グラフ、クラウド同期は、すべて「関連する文脈にすぐ戻れる」ために用意されています。Marianが大切にしている設計の前提を4つにまとめました。
ノート本文の [[リンク]] は相手ノートを参照し、逆方向はバックリンクとして自動で集まります。手作業で索引を作る必要はありません。
選んだノート、リンク、タグ、グラフをまとめてAIに渡せます。回答は、保管庫に書かれた内容に沿ったものになります。
ノート、関連ノート、グラフ、保管庫の状態を同じ画面に並べます。画面の切り替え回数を減らし、参照したい情報へ短い距離で戻れます。
PCでは編集と探索、スマホではクイック入力。どちらから入力しても、同じ保管庫の同じノートに反映されます。
Why Marian
日々の記録・履歴・知識・経験・判断は、ファイルやチャットに散らばり、判断の背景や言葉にしなかった勘どころは、時間とともに失われていきます。Marianは、それらを相互に関連する記憶として蓄積・構造化し、必要なときに取り出せるようにします。
メモ・履歴・知識・経験・判断を、ばらばらのファイルとしてではなく、相互に関連する記憶として蓄積・構造化します。情報は孤立せず、文脈ごとつながった状態で残ります。
過去の判断、その背景にあった文脈、言葉にしていなかった勘どころ、うまくいった経験も失敗も引き継ぎ、グラフを通じて立体的に探索・活用できます。あなたもAIも、同じ記憶の上で考えられます。
AIは単なる検索ではなく、あなたの文脈と記憶を理解したうえで要約・比較・次アクションを提案します。そしてその結果を、再びあなたの記憶へ書き戻します。
記録を記憶資産として蓄積し、あなたとAIが共に学び、過去を引き継ぎ、判断を磨き続けるための土台になります。使うほどに、記憶は厚みを増していきます。
モデルは買えても、組織の記憶は買えない。
汎用エージェントは、あなたの組織の経験を持っていません。Marianは、その経験を毎晩ためて、判断可能な記憶へと育てます。
Experience Base
海馬は記憶庫ではなく、記憶を作り・整理し・関連づけ・思い出せるようにする器官です。Marian Memory は、その6段階で「経験」を判断可能な記憶へ変換します。
Experience Base · 01 / 06
episode
「何が・いつ・誰と・なぜ・結果は」をひとつの経験として記録。事実(Event)を文脈化された経験(Episode)へ。
Experience Base · 02 / 06
consolidation
毎晩、会議・チャット・コードから決定や失敗を抽出し、短期記憶を長期記憶へ統合します。
Experience Base · 03 / 06
recall
検索ではなく再構成。手掛かりからグラフを多ホップで辿り、必要な文脈を組み立てて提示します。
Experience Base · 04 / 06
distillation
忘れるのではなく蒸留。Raw→要約→パターン→原則→方針へ。重要・高リスクな記憶は保護します。
Experience Base · 05 / 06
governance
出典・権限・版・矛盾・品質。誰が言ったか、今も正しいか、誰が見てよいかを記憶ごとに管理します。
Experience Base · 06 / 06
policy
蓄積した経験を方針(Policy)と組織モデルへ蒸留。エージェントが「我々はこう判断する」を使えるように。
Recall
検索は、言葉が一致した記録しか返しません。Marianはそれに加えて「想起」を備えます。人物・時期・場所・結果——断片的な手掛かりから記憶のつながりをたどり、思い出したかった経験そのものへ到達します。人が記憶を呼び出すときの「文脈の匂い」を、機能にしたものです。
「誰と」「いつ頃」「どんな結果だったか」。覚えている断片が、そのまま想起の入口になります。正確な語句を思い出す必要はありません。手掛かりが増えるほど、たどり着く速さも精度も上がります。
「思い出せそうで思い出せない」のは、記憶が消えたのではなく経路が切れている状態です。Marianは手掛かりから記憶のつながりを多段にたどり、目的の経験までの経路を組み立て直します。
同じ結末・同じ相手・同じ時期を共有する経験は、共通の手掛かりを介してつながっています。新しい案件を前にしたとき、過去の類似経験が根拠つきで浮かび上がります。
想起された経験は、AIの回答に背景文脈として編み込まれます。ファイルからの引用とは明確に区別されるため、出典の混同は起きません。あなたの記憶が増えるほど、回答は深くなります。
> recall --cues 新橋 失注
> 2件の経験を再構成 · 出典つき
Organizational Sleep
人の脳は眠っている間に記憶を整理します。Marianは同じ仕組みを「組織の睡眠」として実装しました。3つのエージェントが決まった時刻に走り、その日の記録を整理し、価値の濃い記憶だけを残し、判断の指針へ煮詰めます。記憶の手入れを、意志の力に頼らないこと。それが、記録を資産に変える条件です。
その日の短期記憶から、繰り返し現れたもの・重みのあるものを選び、長期記憶へ昇格します。何度実行しても同じ入力からは同じ結果になる、揺れのない統合です。実行のたびに記録が残ります。
古びて参照されなくなった記憶は、消さずに煮詰めます。生の記録は要約へ、要約はパターンへ、パターンは原則へ。リスクや重要度の高い記憶は保護され、原文はいつでも出典としてたどれます。
繰り返す成功と失敗の原因から「我々はこう判断する」を抽出し、組織の判断指針として束ねます。状況を渡すと、過去の経験に根拠づけられた判断材料が返ってきます。
Math · 記憶の力学
想起・重み付け・忘却は、実装に存在する定数で動いています。以下はその写しです。
活性化伝播
a(v) = a(u) × w(e) × decay
score = a × (1 + salience)
多軸サリエンス
S = Σ wᵢxᵢ × (0.6 + 0.4c)
確信度cが弱い記憶を減衰させる
蒸留の半減期
decay = 0.5^(age / t½)
risk ≥ 0.7 ∨ importance ≥ 0.7 は保護
lib/marian-memory — recall.ts · salience.ts · distill.ts
Scale
記憶はテラバイト級まで育っても、Marianは重くなりません。全部をメモリに載せるのではなく、いま必要な作業集合だけを取り寄せる設計です。組織の知識が増えるほど、エージェントの判断は豊かに、速度はそのまま。
要約のツリーを上から辿り、数億件の断片から関連する記憶だけを引き当てます。知識が増えても、探す範囲は広がりません。
ベクトルを圧縮して分散配置。1TB級の知識でもメモリに収まる粗い索引で候補を絞り、必要な分だけ精密に再評価します。
組織知では「見てよい記憶」だけが候補に出ます。検索の入口でアクセス権をかけるので、越権した情報が回答に混ざりません。
生ログを要約・パターン・原則へ蒸留し続けます。記録の量が10倍になっても、判断に使う記憶は薄く速いまま保たれます。
蓄積した断片は、要約が要約を束ねるピラミッドへ組み上がります。質問は頂上から降りてきて「そのテーマ一帯」をまとめて引き当てます。底辺の総当たりは、もう起きません。
まず軽量な圧縮索引で候補を一気に絞り、残った少数だけを元の精度で読み直します。語句の検索と意味の検索は順位で融合され、互いの取りこぼしを補い合います。
summary pyramid · two-pass retrieval · access-aware search · memory distillation
Citation Trace
「それらしい回答」と「使える回答」の差は、たどれるかどうかです。Marianの回答には根拠となった記録への参照が付き、長い資料は該当ページまで直接たどれます。そして回答の質そのものを数値で監視し、劣化はリリース前に止めます。
回答のどの一文が、どの記録のどの記述に基づくのか。すべての回答に出典が付き、ワンクリックで原文へ戻れます。出典は飾りではなく、回答を検証するための動線です。
数百ページの資料でも、引用は該当ページを直接指します。「たしかどこかに書いてあった」を最初から探し直す時間を、ゼロにします。
回答のうち、出典に裏づけられた主張がどれだけあるか——「根拠率」を継続的に計測します。裏づけの薄い回答は、印象ではなく数値として表面化します。
検索や記憶の仕組みに変更が入るたび、取りこぼしの少なさと出典の正確さを自動で再計測します。基準を割る変更は、本番に届く前に止まります。
Evidence · 実装で答える
夜間の統合も、コストも、回答品質も、画面の中で動いている実物の計測対象です。値は実行の一例。計測器そのものは本番実装です。
> memory-consolidation · daily 03:00
> 3 groups scanned · 2 promoted to long-term
> idempotent: re-run yields identical result
> embed.tokens · 412,800 tok · $0.062
> ask.tokens · 96,400 tok · $0.038
> sink: marian_telemetry_events
> eval:rag — recall@10 0.92 · nDCG 0.88
> groundedness 0.94 · citation 0.96 — PASS
> slo p95 — within target
Yours to Keep
ここに溜まる記憶は、Marianのものではなく、あなたのものです。中身は独自形式に閉じず、いつでも素のファイルとして取り出せます。そして同じ保管庫に、ターミナルからも、あなたのAIエージェントからも届きます。
ノートの実体は、どのエディタでも開ける標準のMarkdownファイルです。[[リンク]]もただのテキスト。移行も、バックアップも、バージョン管理も、あなたの自由です。
作成・検索・グラフ・タスク抽出をコマンドラインから。オフラインでも動作し、毎日のスクリプトやワークフローに組み込めます。画面を開かなくても、記憶は溜まります。
あなたのAIエージェントは、この保管庫を長期記憶として読み書きできます。鍵のスコープと流量の制限を備えた、組織で使うための接続口を用意しました。
スマホの共有メニューから1タップで取り込み、音声メモはそのまま文字になります。放り込んだ瞬間に、名前づけ・分類・タグづけの提案までが終わっています。
FAQ
保存ではなく、想起を設計しています。記録はエピソードとして関連づけられ、夜のあいだに統合され、手掛かりから引き出せる記憶になります。ノートはその入口にすぎません。
RAGは「質問文に似た断片」を返します。Marianはそれに加えて、結末・人物・時期を共有する経験を連想でたどります。検索が外した文脈を、想起が拾います。
すべての回答に出典が付き、原文へ一歩で戻れます。根拠率と引用精度は継続的に計測され、基準を割る変更は本番に届く前に止まります。
ノートの実体は標準のMarkdownファイルです。CLIからもAPIからも同じ保管庫にアクセスでき、全量をいつでも取り出せます。ロックインはありません。
スコープ付きトークンを発行し、APIまたはMCP経由で読み書きできます。あなたのエージェントの長期記憶として機能します。
なりません。候補は圧縮索引と要約ピラミッドで先に絞り込むため、探索量は「いま必要な作業集合」に比例します。知識の総量には比例しません。
トップページでGoogleログインを選ぶと、認証完了後にワークスペースへ遷移します。LPへ戻って迷うのではなく、すぐにメモ、調査、AI文脈を積み上げ始められます。
Supabaseのブラウザ認証情報が設定されている環境ではOAuthが有効になります。未設定のローカル環境では、ボタンを無効化して状態を明示します。